

Movie Recommendation System using Neo4j and Python.


There are many ways to recommend movies to someone. You could simply suggest a movie that you liked and think the other person might enjoy. However, a movie recommendation system using Neo4j and python can create a list of movies that the user might actually like.
Neo4j is a graph database that can be used to store and query data. In this article, we will use Neo4j to store information about movies and connect movies with each other using their similarity score. We will also use python to create a script that will recommend movies to the user.
Firstly we need to prepare our dataset for neo4j. For that, we will be using the movielens dataset which can be downloaded from the grouplens website(Group Lens). The graph database we are going to create in Neo4j is going to have nodes that contain the names of the movies and relations between pairs of movie nodes that contain the similarity score between them.
1. Load Dataset
import Libaries
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
download dataset
!wget https://files.grouplens.org/datasets/movielens/ml-25m.zip
genome_scores_data = pd.read_csv(‘genome-scores.csv’)
movies_data = pd.read_csv(‘movies.csv’)
ratings_data = pd.read_csv(‘ratings.csv’)
genome_scores_data.head()
movies_data.head()
ratings_data.head()
 Note: If your system has low memory, try using a smaller dataset. The preprocessing part consumes a lot of memory
Note: If your system has low memory, try using a smaller dataset. The preprocessing part consumes a lot of memory
2. Preprocessing
Now we need to create two datasets, one for the movie nodes and the other for the movie similarity relation.
Movies Dataset
movies_df = movies_data.drop(['genre','movieId'], axis = 1)
movies_df.to_csv('movies.csv', sep='|', header=True, index=False)
Movie Similarity Dataset
we are going to create a movie similarity matrix using cosine similarity. The matrix is going to be created by mixing cosine similarities of movie tags, movie genres, and movie ratings.
the movie_tag dataframe is created using the genome scores by merging it with the movie dataset using movie_id as key.
scores_pivot = genome_scores_data.pivot_table(index = ["movieId"],columns = ["tagId"],values = "relevance").reset_index()
mov_tag_df = movies_data.merge(scores_pivot, left_on='movieId', right_on='movieId', how='left')
mov_tag_df = mov_tag_df.fillna(0)
mov_tag_df = mov_tag_df.drop(['title','genres'], axis = 1)
mov_tag_df.head()
The movie genre dataset is generated by splitting the genre column from the movie dataframe into individual columns for each genre. the value of each cell is set to 1 if the movie belongs to that genre and 0 otherwise.
def set_genres(genres,col):
if genres in col.split('|'): return 1
else: return 0
mov_genres_df = movies_data.copy()
mov_genres_df["Action"] = mov_genres_df.apply(lambda x: set_genres("Action",x['genres']), axis=1)
mov_genres_df["Adventure"] = mov_genres_df.apply(lambda x: set_genres("Adventure",x['genres']), axis=1)
mov_genres_df["Animation"] = mov_genres_df.apply(lambda x: set_genres("Animation",x['genres']), axis=1)
mov_genres_df["Children"] = mov_genres_df.apply(lambda x: set_genres("Children",x['genres']), axis=1)
mov_genres_df["Comedy"] = mov_genres_df.apply(lambda x: set_genres("Comedy",x['genres']), axis=1)
mov_genres_df["Crime"] = mov_genres_df.apply(lambda x: set_genres("Crime",x['genres']), axis=1)
mov_genres_df["Documentary"] = mov_genres_df.apply(lambda x: set_genres("Documentary",x['genres']), axis=1)
mov_genres_df["Drama"] = mov_genres_df.apply(lambda x: set_genres("Drama",x['genres']), axis=1)
mov_genres_df["Fantasy"] = mov_genres_df.apply(lambda x: set_genres("Fantasy",x['genres']), axis=1)
mov_genres_df["Film-Noir"] = mov_genres_df.apply(lambda x: set_genres("Film-Noir",x['genres']), axis=1)
mov_genres_df["Horror"] = mov_genres_df.apply(lambda x: set_genres("Horror",x['genres']), axis=1)
mov_genres_df["Musical"] = mov_genres_df.apply(lambda x: set_genres("Musical",x['genres']), axis=1)
mov_genres_df["Mystery"] = mov_genres_df.apply(lambda x: set_genres("Mystery",x['genres']), axis=1)
mov_genres_df["Romance"] = mov_genres_df.apply(lambda x: set_genres("Romance",x['genres']), axis=1)
mov_genres_df["Sci-Fi"] = mov_genres_df.apply(lambda x: set_genres("Sci-Fi",x['genres']), axis=1)
mov_genres_df["Thriller"] = mov_genres_df.apply(lambda x: set_genres("Thriller",x['genres']), axis=1)
mov_genres_df["War"] = mov_genres_df.apply(lambda x: set_genres("War",x['genres']), axis=1)
mov_genres_df["Western"] = mov_genres_df.apply(lambda x: set_genres("Western",x['genres']), axis=1)
mov_genres_df["(no genres listed)"] = mov_genres_df.apply(lambda x: set_genres("(no genres listed)",x['genres']), axis=1)
mov_genres_df.drop(['title','genres'], axis = 1, inplace=True)
mov_genres_df.head()
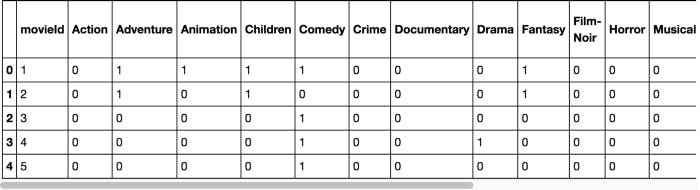
Movie Rating Dataset
The movie rating dataset is created using movies and rating datasets. it contains the rating, rating count, and year group of the movie. The year group has values from 0–5 and the rating count has values from 0–5.
function to extract the year from title
def set_year(title):
year = title.strip()[-5:-1]
if year.isnumeric():
return int(year)
else:
return 1800
function to set year group
def set_year_group(year):
if (year < 1900): return 0
elif (1900 <= year <= 1975): return 1
elif (1976 <= year <= 1995): return 2
elif (1996 <= year <= 2003): return 3
elif (2004 <= year <= 2009): return 4
elif (2010 <= year): return 5
else: return 0
function to set rating count group
def set_rating_group(rating_counts):
if (rating_counts <= 1): return 0
elif (2 <= rating_counts <= 10): return 1
elif (11 <= rating_counts <= 100): return 2
elif (101 <= rating_counts <= 1000): return 3
elif (1001 <= rating_counts <= 5000): return 4
elif (5001 <= rating_counts): return 5
else: return 0
movies = movies_data.copy()
movies['year'] = movies.apply(lambda x: set_year(x['title']), axis=1)
movies['year_group'] = movies.apply(lambda x: set_year_group(x['year']), axis=1)
movies.drop(['title','year'], axis = 1, inplace=True)
creating rating dataframe
agg_movies_rat = ratings_data.groupby(['movieId']).agg({'rating': [np.size, np.mean]}).reset_index()
agg_movies_rat.columns = ['movieId','rating_counts', 'rating_mean']
agg_movies_rat['rating_group'] = agg_movies_rat.apply(lambda x: set_rating_group(x['rating_counts']), axis=1)
agg_movies_rat.drop('rating_counts', axis = 1, inplace=True)
mov_rating_df = movies.merge(agg_movies_rat, left_on='movieId', right_on='movieId', how='left')
mov_rating_df = mov_rating_df.fillna(0)
mov_rating_df.drop(['genres'], axis = 1, inplace=True)
mov_rating_df.head()
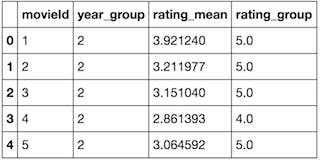
The movie similarity Matrix
mov_tag_df = mov_tag_df.set_index('movieId')
mov_genres_df = mov_genres_df.set_index('movieId')
mov_rating_df = mov_rating_df.set_index('movieId')
the final cosine similarly score is calculated by adding the similarity scores of movie tags, movie genres, and movie ratings with the weights of 0.5,0.25 and 0.25 respectively
cos_tag = cosine_similarity(mov_tag_df.values)*0.5
cos_genres = cosine_similarity(mov_genres_df.values)*0.25
cos_rating = cosine_similarity(mov_rating_df.values)*0.25
cos = cos_tag+cos_genres+cos_rating
cols = mov_tag_df.index.values
inx = mov_tag_df.index
movies_sim = pd.DataFrame(cos, columns=cols, index=inx)
movies_sim.head()
function to find movies similar to a given movie
top 5 similar movies are selected using their relevance score.
def get_similar(movieId):
df = movies_sim.loc[movies_sim.index == movieId].reset_index(). \
melt(id_vars='movieId', var_name='sim_moveId', value_name='relevance'). \
sort_values('relevance', axis=0, ascending=False)[1:6]
return df
movies_similarity = pd.DataFrame(columns=['movieId','sim_moveId','relevance'])
for x in movies_sim.index.tolist():
movies_similarity = movies_similarity.append(get_similar(x))
movies_similarity.head()
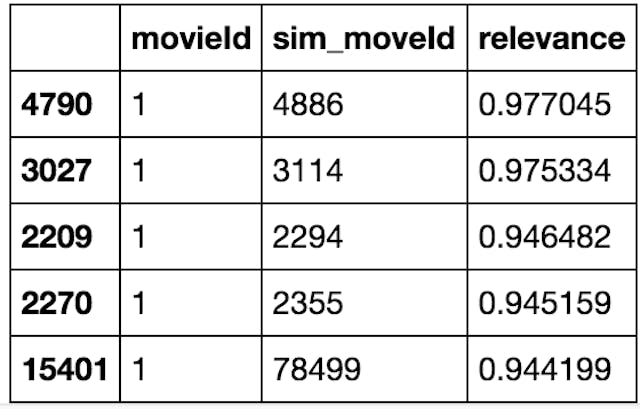
movies_similarity.to_csv('movies_similarity.csv', sep='|', header=True, index=False)
3. Loading data to Neo4j
Create a new database in Neo4j using the "Add Graph" option. Then click the 3 dots near your graph -> Open Folder -> Import. add the CSV files to the newly opened folder. Then Open the browser to your database and the cipher commands.
Let's load the movie Nodes
LOAD CSV WITH HEADERS FROM "file:///movies.csv" AS row
FIELDTERMINATOR '|'
CREATE (:Movies {movieId: row.movieId, title: row.title, rating_mean: row.rating_mean});
create indexes
CREATE INDEX ON :Movies(movieId);
Now the Relations.
LOAD CSV WITH HEADERS FROM "file:///movies_similarity.csv" AS row
FIELDTERMINATOR '|'
MATCH (movie1:Movies {movieId: row.movieId})
MATCH (movie2:Movies {movieId: row.sim_moveId})
MERGE (movie1)-[:SIMILAR {relevance: row.relevance}]->(movie2);
Now we have our graph database

4. Recommending using python
Now we will create a python script to query the graph database and recommend movies
Import Libraries
from neo4j import GraphDatabase
from sentence_transformers import SentenceTransformer, util
import pandas as pd
import pickle
import torch
we are going to use a language transformer to find the correct name of the movie entered by the user (this takes care of spelling mistakes). we need to create embeddings for the movie names to use a sentence transformer.
model = SentenceTransformer('all-MiniLM-L6-v2')
movies = pd.read_csv('movie_list.csv')
movie_names = movies["title"].apply(str).values.tolist()
movie_embeddings = model.encode(movie_names)
Next, we initialize the Neo4j connection.
uri = "neo4j://localhost:7687"
driver = GraphDatabase.driver(uri, auth=("root", "password"))
Now we need to create a function that queries the graph database and returns the result.
def match(tx, movie_name):
movie_list = []
result = tx.run(
"MATCH (m:Movies )<-[r:SIMILAR]-(n:Movies) WHERE m.title = '" + movie_name + "' RETURN n.title ")
for record in result:
movie_list.append(record[0])
return movie_list
Finally, the driver function to get the user input and print the recommended movies
def main():
with driver.session() as session:
movie_name = input("Enter the movie name: ")
movie_name_embedding = model.encode([movie_name])
cosine_scores = util.pytorch_cos_sim(
movie_name_embedding, movie_embeddings)[0]
top_result = torch.topk(cosine_scores, k=1)
movie_name = movie_names[top_result[1][0]]
print(match(session, movie_name))
driver.close()
main()

That's it, folks. You have your own basic movie recommendation system using Neo4j.
I used the following blog as a reference for my work Design a Movie Recommendation System with using Graph Database (neo4j)
If you like my work, please connect with me on LinkedIn
Consider buying me a coffee if you liked my post BuyMeCoffee